A Bag of Tricks for Deep Reinforcement Learning
 The KUKA bin environment visualized in NVIDIA IsaacGym
The KUKA bin environment visualized in NVIDIA IsaacGymWhen I first started studying reinforcement learning (RL), I implemented Proximal Policy Optimization (PPO) from scratch using only the psuedocode on OpenAI’s website. It didn’t work and failed to obtain nearly any reward on most OpenAI Gym environments. It took a few more months of debugging, reading other RL implementations, and talking to colleagues to get things working. My conversations with other Georgia Tech students revealed that initially struggling to do basic things with RL was not uncommon. These blog posts do a great job of explaining the difficulty with RL and really resonate with my own experiences.
In hindsight, there was no single major flaw with my initial PPO implementation, but rather many small tricks and optimizations that were missing. The purpose of this post is to enumerate these tricks and provide references to code where they are implemented. They are roughly ordered in descending order of importance. Knowledge of some of these tricks is only necessary if you are implementing an RL algorithm from scratch, as most public implementations will already include them. However, knowing of their existence will enable you to debug more effectively and make changes more intelligently.
Different RL implementations will include a slightly different set of tricks. As evidence of their importance, check out this figure (below) from the paper Deep Reinforcement Learning that Matters. The authors show empirically that different popular implementions of the same RL algorithm differ significantly in performance on standard RL benchmarks, even when controlling for hyperparameters and network architecture.

Figure 6 from Deep Reinforcement Learning that Matters, plotting the performance of different RL implementations averaged over 5 random seeds. These variations can be explained by differences in implementation and different PyTorch/TF versions.
Now for some disclaimers – nearly all of my experience comes from training on-policy algorithms for continuous control, so there may be useful tips for discrete/off-policy settings that I’m missing. Also, RL is a super-hot field and perhaps some of the content in this post is already outdated. Hopefully, this blog is at least useful to someone starting out like I was. Please don’t hesitate to reach out to me if you think there is something important missing!
Most of the examples will come from either of these two RL implementations:
Implementing an RL algorithm from scratch is an excellent way to learn. However, if you just need to get something working quickly, you should instead just fork a popular repo and start from there. Here are some suggestions:
Contents:
- Observation and Normalization Clipping
- Dense Rewards
- Hyperparameter Tuning
- Gradient Normalization and Clipping
- Reward Normalization and Clipping
- Advantage Standardization
- Bootstrapping Incomplete Episodes
- Generalized Advantage Estimation
- Entropy Decay
- Value Network Loss Clipping
- Learning Rate Scheduling
Thanks to Andrew Szot and Mathew Piotrowicz for reading drafts of this and providing feedback.
Observation Normalization and Clipping
In RL, the inputs to the policy and value networks are observations, which can consist of values that differ by orders of magnitude. For example, if you are learning a policy to control a robot, your observation could contain joint angles ranging from $ -\frac{\pi}{2} $ to $ \frac{\pi}{2} $ radians and a robot position coordinate that lies between 0 and 1000 meters. Normalizing the input space to eliminate this difference in scale leads to more stable training and faster convergence. This should be nothing new to those with prior experience training neural networks.
The two most common methods for preprocessing are standardization and rescaling. Standardization refers to subtracting the mean and dividing by the standard deviation of the data so that each dimension approximates a standard normal distribution. Rescaling means mapping the data to the range $ \left[0, 1\right] $ by subtacting the min and dividing by the range. In either case, clipping should also be applied after normalization. Neural networks are bad at extrapolation, and outliers can produce unexpected outputs. In my work, observations are clipped to $[-5.0, 5.0]$ after standardization.
In supervised learning, statistics calculated over the training set are used to normalize each sample. In RL, this isn’t possible because the dataset (consisting of interactions with the environment) is collected online and the statistics change continuously. Because of this, you need to calculate an online mean and standard deviation. Most RL codebases use an implementation of Welford’s Online Algorithm like this one from Stable Baselines3.
This online approach is best when your algorithm needs to work on many different environments. However, it often causes an initial drop in performance (red circle below) as the mean and standard deviation move rapidly early in training due a small sample size and exploration.
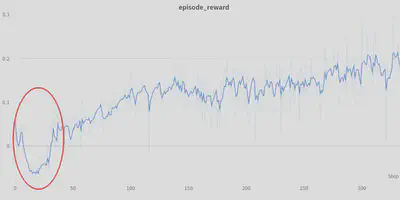
Alternatively, if you have good prior knowledge about the bounds of the observation space, you can just rescale your data to the range [-1, 1] or [0, 1], like what they do here.
Note: A common bug when replaying trained policies is the failure to save and load normalization statistics. A policy network will not work during test time if the inputs are not preprocessed the same way they were during training.
Code examples
Dense Rewards
This tip will only be applicable if you are applying RL to a new task where you have the freedom to specify a reward function, rather than training on standard RL benchmarks where the reward function is part of the task.
Sparse rewards are difficult for RL algorithms to learn from. If possible, try making your reward dense, meaning that at every timestep the agent recieves an informantive reward as a function of the current state, previous state, and action taken. For example, instead of rewarding an agent +1.0 for reaching a goal and 0.0 otherwise, try giving a reward at every timestep that is propotional to progress towards the goal. Of course, this requires some prior knowledge of what progress looks like and can limit the types of solutions that your policy discovers.

Figure 3 from ALLSTEPS: Curriculum-driven Learning of Stepping Stone Skills depicting the stepping-stone task
For example, in the paper ALLSTEPS: Curriculum-driven Learning of Stepping Stone Skills, the authors train a bipedal robot to hit a series of stepping stones. A naive reward design would give +1.0 if the robot’s foot hit the center of the foot target (depicted above), and 0.0 otherwise. Instead of doing this, the authors specify a reward function of
$$ r_{target} = k_{target}\exp(-d/k_d) $$
where $d$ is the distance from the foot to the target, and $ k_{target}$ and $k_d$ are hyperparameters. If the robot’s foot makes any contact with the stepping stone, it receives a reward. The closer the foot is to the center of the block, the higher the reward. The authors explain:
In the initial stages of training, when the character makes contact with the target, the contact location may be far away from the center. Consequently, the gradient with respect to the target reward is large due to the exponential, which encourages the policy to move the foot closer to the center in the subsequent training iterations.
Without the dense reward, there would be no reward gradient across the state space, which makes learning more difficult.
Hyperparameter Tuning
RL is notoriously sensitive to hyperparameters and there is no one-size-fits-all for good hyperparameter values. Typically, different implementations and different applications will require different hyperparameters. Here are just a few hyperparameters that could make a difference:
- reward function term coefficients
- number of policy updates and samples per update
- learning rate
- entropy coefficient
- value coefficient
- network architecture
- batch size and number of epochs per policy update
- clipping values for gradients, rewards, values, observations, and the PPO loss
The good thing is Weights & Biases has a powerful pipeline for automated, distributed hyperparameter sweeps. They support random search, grid search, and Bayesian search.
Gradient Normalization and Clipping
This is another one that could be obvious if you have a background in deep learning already. Normalizing the gradient of the value and policy networks after each backward pass can help avoid numerical overflow, exploding gradients, or destructively large parameter updates. Other tricks for avoiding these same issues include reward normalization and clipping, value function loss clipping, and advantage standardization.
Code examples:
Reward Normalization and Clipping
Typically, it is best not to have reward values that differ by many orders of magnitude. For example, in the paper Playing Atari with Deep Reinforcement Learning, the authors clip all rewards to the range $ \left[-1, 1\right] $.
Since the scale of scores varies greatly from game to game, we fixed all positive rewards to be 1 and all negative rewards to be −1, leaving 0 rewards unchanged. Clipping the rewards in this manner limits the scale of the error derivatives and makes it easier to use the same learning rate across multiple games. At the same time, it could affect the performance of our agent since it cannot differentiate between rewards of different magnitude.
– Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. “Playing atari with deep reinforcement learning.” arXiv preprint arXiv:1312.5602 (2013).
In addition to just clipping the rewards, you can also keep a running mean and standard deviations of rewards to standardize rewards or returns (discounted rewards).
Code examples:
- pytorch-a2c-ppo-acktr-gail
- Rewards are processed by these two environment wrappers from Stable Baselines3
- stable_baselines3.common.atari_wrappers.ClipRewardEnv
- stable_baselines3.common.vec_env.VecNormalize.normalize_reward
Advantage Standardization
Before calculating a loss for the policy network, advantages are computed and then standardized, such that about half of the advantages are positive and about half are negative. This is done for stability of training and variance reduction. Here is an excerpt from HW2 of the Berkely Deep RL course:
A trick which is known to usually boost empirical performance by lowering variance of the estimator is to center advantages and normalize them to have mean of 0 and a standard deviation of 1. From a theoretical perspective, this does two things:
- Makes use of a constant baseline at all timesteps for all trajectories, which does not change the policy gradient in expectation.
- Rescales the learning rate by a factor of 1/σ, where σ is the standard dev of the empirical advantages.
Code Examples
Bootstrapping Incomplete Episodes
In most RL pipelines, the environment runs for a pre-specified number of steps before a policy update occurs. This means the sample collection will often end before the episode does, meaning the policy will be updated with samples from incomplete episodes. When returns (sum of discounted future rewards) are calculated, this truncation makes it seem as if the agent received zero reward for the rest of the episode. To correct this error, the return computation can be “bootstrapped” with the value estimate of the final state.
The dictionary definition of bootstrap:
Bootstrap (verb)
- get (oneself or something) into or out of a situation using existing resources.
“the company is bootstrapping itself out of a marred financial past”Source: OxfordLanguages
In the context of RL, bootstrapping means estimating value function or Q-function targets using estimates from the same value or Q-function (“existing resources”). Bootstrapping is done with every sample in temporal difference learning (TD-learning) and Q-learning. In TD learning, the value estimates are :
$$\hat{V}(s_0) = r_0 + \gamma V(s_{1})$$
At the other end of the spectrum, values can be estimated for a state $s_0$ without bootstrapping using complete trajectories that start at $s_0$. The value estimate for a state $ s_0 $ from a single rollout from $s_0$ to $s_H$ is:$$ \hat{V}(s_0) = \sum_{t = 0}^{H}\gamma^t r_t $$
When the episode gets truncated at $ h < H $, we can bootstrap this calculation using the value estimate of the final state. Note how $r_h$ is discarded and replaced with $V(s_h)$.
$$ \hat{V}(s_0) = \sum_{t = 0}^{h - 1}\gamma^t r_t + \gamma^{h}V(s_{h}) $$
Bootstrapping can help, but it can also hurt. It reduces variance in the computation of returns at the expense of introducing a bias from the value network. Here are some excerpts from Sutton and Barto’s textbook, where they place bootstrapping in the “Deadly Triad” of instability and divergence.
…bootstrapping methods using function approximation may actually diverge to infinity. …Bootstrapping often results in faster learning because it allows learning to take advantage of the state property, the ability to recognize a state upon returning to it. On the other hand, bootstrapping can impair learning on problems where the state representation is poor and causes poor generalization.
– Barto, Sutton. Reinforcement Learning: An Introduction. 2018
Controlling this bias-variance tradeoff with bootstrapping is a central idea in Generalized Advantage Estimation (GAE).
This kind of bootstrapping should also be applied to timeout terminations on continouous tasks. Continuous tasks are those where episodes do not end once a particular objective is achieved. One example of this is robot locomotion, where success could be foward walking that continues indefinitely. However, in order to increase sample diversity, episodes are typically subject to a timeout. Since the timeout is independent of the robot’s performance, the returns should be bootstrapped.
Code examples:
- pytorch-a2c-ppo-acktr-gail
- In this computation, the tensor
self.bad_masksindicates when bootstrapping should occur. If its value is 0, then the reward at the terminal timestep is replaced with the value estimate of the terminal state.
- In this computation, the tensor
Generalized Advantage Estimation
Generalized Advantage Estimation (GAE), from the paper from the paper High-Dimensional Continuous Control Using Generalized Advantage Estimation, provides a continuous bias-variance tradeoff through controlling the amount of bootstrapping via a parameter $\lambda$. The formula for computing advantages is given below, but I highly recommend reading the actual paper if you are going to program this yourself.
$$ \hat{A}^{GAE(\gamma, \lambda)}_t = \sum^\infty_{l=0} (\gamma \lambda)^l \delta^V_{t+l} $$ $$\delta_{t}^V = r_t + \gamma V(s_{t+1}) -V(s_t)$$The TD-learning value update is a special case of GAE when $\lambda = 0$. When $\lambda = 1$, no bootstrapping occurs. Most of the time, I set $\gamma = 0.99$ and $\lambda = 0.95$.
The above two equations from the paper deal with the infinite time horizon case. Dealing with terminations and bootstrapping in the finite-horizon case can be confusing, so I’ve provided some equations below. Again, assume these are estimates of advantages and values from a single trajectory from $s_0$ to $s_H$ where truncation occurs at timestep $h < H$.
Finite time horizon, no bootstrapping (full episode)
Note that $\delta_H$ becomes $r_H - V(s_H)$ because $V(s_{H+1})$ is zero.
$$\hat{A}^{GAE(\gamma, \lambda)}_t= \sum_{t=0}^{H-1} (\gamma \lambda)^t \delta^t + (\gamma \lambda)^H (r_H - V(s_H))$$ $$\hat{V}^{GAE(\gamma, \lambda)}_t= \hat{A}^{GAE(\gamma, \lambda)}_t + V(s_o)$$
Finite time horizon with bootstrapping
Note that $r_h$ is replaced with $V(s_h)$, which makes the final term zero.
$$\hat{A}^{GAE(\gamma, \lambda)}_t= \sum_{t=0}^{h-1} (\gamma \lambda)^t \delta^t $$ $$\hat{V}^{GAE(\gamma, \lambda)}_t= \hat{A}^{GAE(\gamma, \lambda)}_t + V(s_o)$$
Code examples:
- pytorch-a2c-ppo-acktr-gail
- RL Games
- As far as I can tell, RL Games does not do any bootstrapping of truncated episodes or timeouts. No information about the nature of terminations is received from the environment, and there is no condition where the advantage of a timestep is set to zero.
Entropy Decay
The exploration-exploitation tradeoff is a fundamental problem in RL which is usually dealt with through experimentation or hyperparamter tuning. Generally, you want more exploration early in training. The most basic way to increase exploration is to increase the entropy of the policy used to obtain environment samples. Assuming the policy outputs to a Gaussian distribution over actions, the entropy is proportional to the log of the variance. In on-policy algorithms like TRPO and PPO, entropy can be controlled indirectly via a loss term that reward entropy. In off-policy algorithms like DDPG, SAC, or TD3, noise is added to the output of a deterministic policy during sample collection. The entropy of the sampling process can be directly controlled via this noise. Starting with a high entropy coefficient/high-variance noise and decaying the desired entropy to zero may yield the desired exploration-exploitation behavior.
In my own work in legged locomotion, I have often found this uncessary. The majority of the time, I use PPO and set the entropy coefficient to 0.0 for the entirety of training. Perhaps the chaotic underactuated dynamics of the legged robot eliminates the need for extra exploration noise.
Code example:
Value Network Loss Clipping
This is another trick aimed at controlling the behavior of the gradients and preventing excessively large updates. The value function is trained on a mean-squared error (MSE) loss where the target values are value estimates from policy rollouts. This is contrast to supervised learning, where the targets are stationary ground-truth labels. Because the targets themselves are estimates derived from a stochastic sampling process, inaccurate targets which produce large errors can occur.
Value network loss clipping roughly constrains the change in value estimates between policy iterations to a “trust region” of $\pm\ \epsilon$ from the old value estimates. (Constraining updates to a trust region is the central idea behind TRPO and PPO, but for action probabilities instead of value estimates.) The loss calculation is given below, where backpropogation happens through $V_{new}(s_0)$ only.
$$ V_{clip}(s_0) = V_{old}(s_0) + \text{Clip}(V_{new}(s_0) - V_{old}(s_0),\ - \epsilon,\ \epsilon) $$ $$\mathcal{L}_{\text{MSE-Clip}} = (V_{clip}(s_0) - V_{target}(s_0))^2 $$ $$\mathcal{L}_{\text{MSE}} = (V_{new}(s_0) - V_{target}(s_0))^2 $$ $$\mathcal{L}_{\text{final}} = \text{max}(\mathcal{L}_{\text{MSE-Clip}}, \mathcal{L}_{\text{MSE}})$$$\epsilon$ is usually set to something like $0.2$. Note that $V_{new}(s_0)$ could end up slightly outside of $\left[V_{old}(s_0) - \epsilon, V_{old}(s_0) + \epsilon\right]$. This is because the values themselves are not clipped, rather, the updates to the value function stop happening when clipping occurs ($\epsilon$ is just a constant with no dependency on the value network parameters – no backprop can occur through $\epsilon$). This could also be due to parameter updates from loss terms corresponding to states other than $s_0$.
Honestly, the clipped value update is rather confusing, especially at first. In my analysis, I discovered an edge case where value updates should occur, but don’t (figure below). Moving $V_{new}$ in the direction of $V_{target}$ will move $V_{new}$ closer to the trust region, but this update doesn’t occur because the distance from the nearest edge of the trust region to $V_{target}$ is greater than the distance between $V_{target}$ and $V_{new}$. However, perhaps the clipped MSE loss makes it unlikely that $V_{new}$ will end up far outside the trust region in the first place.

Strangely, I couldn’t find much mention of value network loss clipping in the academic literature or on the internet, and I don’t know if this technique goes by another name. I only found this paper (“PPO-style pessimistic clipping”) and this GitHub issue. I don’t think “pessimistic clipping” is an appropriate name, since “pessimism” in the context of value functions in RL usually means values are underestimated.
Code Examples:
Learning Rate Scheduling
A linearly decreasing learning rate is a common technique for training neural networks. The idea is that in the beginning of training, the optimizer should take large steps to minimize loss rapidly, while near the end, the steps should be smaller to facilitate convergence to a local optima.
A fancier way to control the learning rate is to adaptively set it based on a desired KL-divergence between policy iterations. In most of my work, I use the RL Games implementation of an adaptive learning rate with an initial learning rate of 1e-5. Here is what the learning rate and KL-divergence plots usually looks like:
Code examples for linear learning rate decay:
Code for adaptive learning rate:
Thanks for reading!
Jeremiah Coholich
Robotics PhD Student
My research interests include deep learning, reinforcement learning, and legged robots.